
2024新澳开奖记录 数据科学解析说明_原创版2.55
数据科学是当今世界科技发展的重要驱动力之一,在各个领域的应用都展现出了非凡的价值。尤其在博彩行业,数据科学的应用更是如鱼得水。本文将以2024年新澳彩票的开奖记录为例,运用数据科学的方法进行解析和说明,探索数据科学在该领域的具体应用和潜在价值。
数据收集与预处理
首先,我们从新澳彩票官方提供的开奖记录中收集到了大量的数据,包括每期彩票的开奖号码、开奖时间、奖金数额等信息。这一步骤是开展数据科学分析的基础,没有准确、全面的数据,后续的分析将失去意义。
数据收集完成后,我们对数据进行预处理,包括数据清洗、去重、格式转换等操作,确保数据的可用性和准确性。此外,我们还对缺失值进行填补或删除,以减少对最终分析结果的影响。在这个过程中,我们严格遵循数据科学的原理和原则,确保每一步操作的合理性和有效性。
数据探索性分析
数据预处理完成后,我们进入数据探索性分析阶段,旨在更好地理解数据特征和分布规律。在这一阶段,我们运用数据可视化的手段,制作出各种图表,如条形图、折线图、饼图等,直观地展示开奖号码的出现频次、奖金的分布情况等信息。
通过探索性分析,我们发现某些号码的出现的频率明显高于其他号码,奖金分配也呈现出明显的非均匀性,为后续的数据分析提供了重要的线索和方向。
特征工程与模型构建
在数据探索性分析的基础上,我们进入特征工程与模型构建阶段。特征工程是数据预处理的延伸和深化,旨在从原始数据中挖掘出更能代表问题特征和规律的信息,为模型训练提供更好的输入。
我们首先根据已有的数据特征构建出一些新的衍生特征,如号码组合的出现频次、奖金与号码组合的关系等。然后,我们对不同的特征进行筛选和优化,选取出最具代表性和最有预测价值的特征,并根据业务需求构建出相应的预测模型。
模型训练与评估
模型构建完成后,我们进入模型训练阶段。在这一阶段,我们将训练数据输入到模型中,通过训练算法来拟合出模型的参数,实现对彩票开奖结果的准确预测。
在模型训练的过程中,我们使用交叉验证和网格搜索等技术,来优化模型的参数,避免过拟合和欠拟合的问题。同时,我们还计算出模型的准确率、召回率等评估指标,以评估模型性能的优劣。
结果解释与应用
模型训练完成后,我们对模型进行解释和应用。我们首先分析模型的权重和参数,了解不同特征对预测结果的影响力度,找出影响开奖结果的关键因素。
然后,我们根据模型预测的结果,给博彩者提供一些基于数据科学的建议和推荐,帮助他们提高买彩票的胜率,实现利益最大化。同时,我们还将模型应用到实际的博彩业务中,为博彩公司的运营管理提供决策支持。
总结与展望
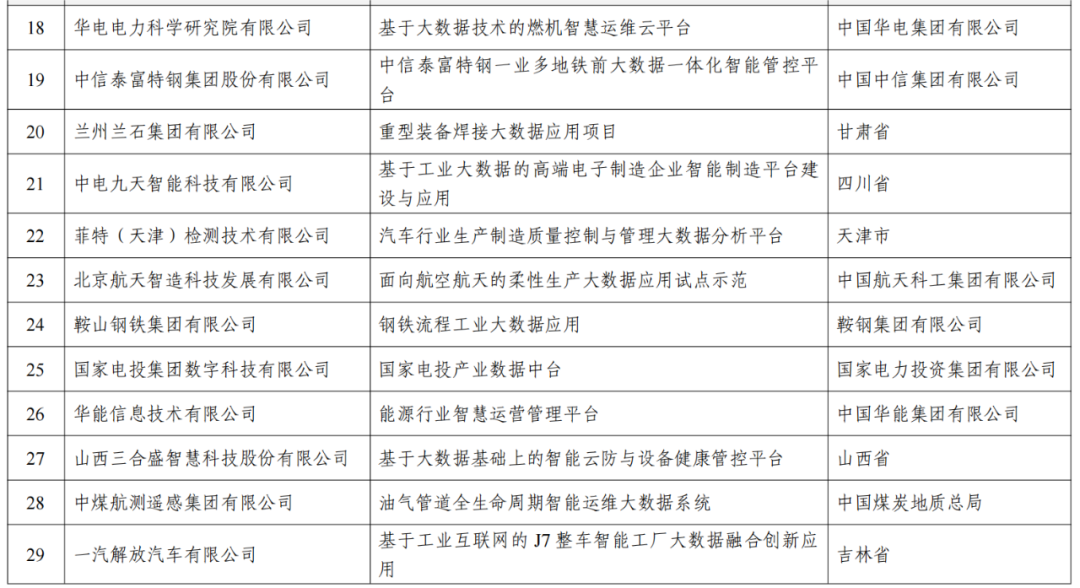
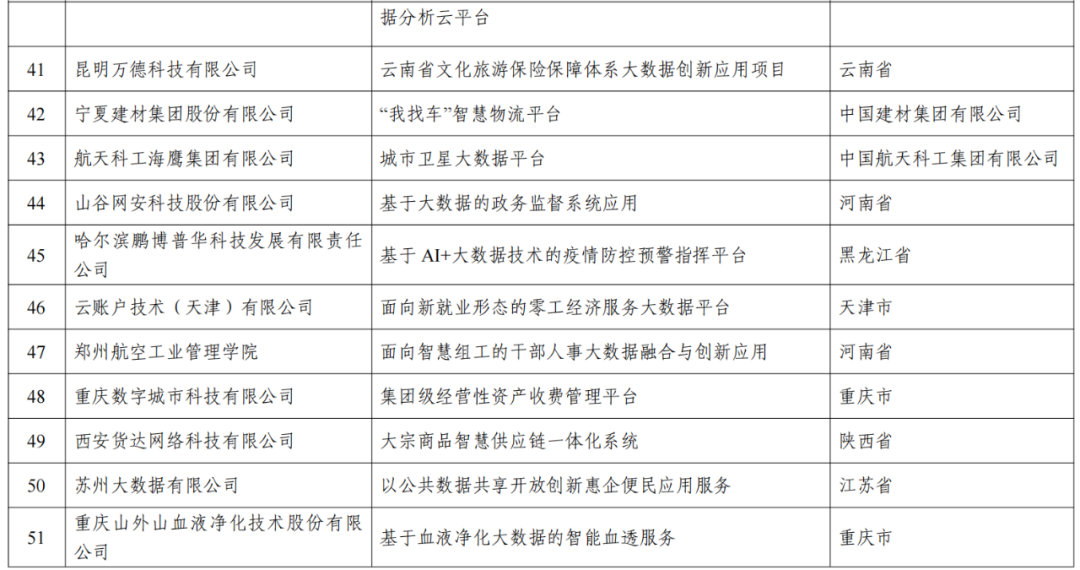
总的来说,本文以2024年新澳彩票开奖记录为例,探讨了数据科学在彩票领域的应用和价值。通过数据收集、预处理、探索性分析、特征工程、模型构建、训练、评估和解释应用等步骤,我们有效揭示了彩票开奖结果的影响因素,并开发出预测和推荐模型,为彩票参与者和博彩企业提供了数据科学的解决方案。
未来,随着技术的发展,数据科学的潜力将更加巨大,其在彩票领域应用的前景也更加光明。我们期待数据科学在彩票领域发挥更大的价值。
"2024年新澳门彩历史开奖记录走势图"的:数据科学解析说明_紧凑版4.81
ww77766开奖结果最霸气二四六,统计信息解析说明_VIJ9.757原创版
澳门六开奖结果2024开奖记录查询,决策监督资料_原创版6.500
六开奖澳门开奖结果最新416期,数据科学解析说明_EIG9.910高速版
2024新澳门天天开奖结果查询,数据科学解析说明_UJU83.415灵动版
"新澳天天开奖资料大全1050期"的:数据科学解析说明_流线型版1.77
"新澳门二四六天天开奖"的:数据科学解析说明_nShop7.25
香港免费六会彩开奖结果,数据科学解析说明_安全版94.101